Network theorists working for the US military have worked out how to identify the small “seed” group of people who can spread a message across an entire network.
Viral messages begin life by infecting a few individuals and then start to spread across a network. The most infectious end up contaminating more or less everybody.
Just how and why this happens is the subject of much study and debate. Network scientists know that key factors are the rate at which people become infected, the “connectedness” of the network and how the seed group of individuals, who first become infected, are linked to the rest.
It is this seed group that fascinates everybody from marketers wanting to sell Viagra to epidemiologists wanting to study the spread of HIV.
So a way of finding seed groups in a given social network would surely be a useful trick, not to mention a valuable one. Step forward Paulo Shakarian, Sean Eyre and Damon Paulo from the West Point Network Science Center at the US Military Academy in West Point.
These guys have found a way to identify a seed group that, when infected, can spread a message across an entire network. And they say it can be done quickly and easily, even on relatively large networks.
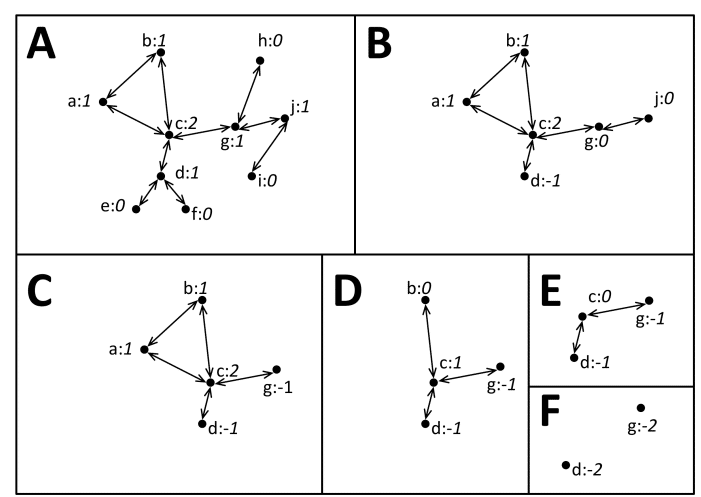
Their method is relatively straightforward. It is based on the idea that an individual will eventually receive a message if a certain proportion of his or her friends already have that message. This proportion is a critical threshold and is crucial in their approach.
Having determined the threshold, these guys examine the network and look for all those individuals who have more friends than this critical number. They then remove those who exceed the threshold by the largest amount.
In the next, step, they repeat this process, looking for all those with more friends than the critical threshold and pruning those with the greatest excess. And so on.
This process finishes when there is nobody left in the network who has more friends than the threshold. When this happens, whoever is left is the seed group. A message sent to each member of this group can and should spread to the entire network.
That’s a slick approach to a well-known problem. What’s got network scientists bogged down in the past is that they’ve always couched this conundrum in terms of finding the smallest seed group. Proving that the group you’ve found is the smallest really is a tricky problem.
But Shakarian and co make no such claim. “We present a method guaranteed to find a set of nodes that causes the entire population to activate – but is not necessarily of minimal size,” they say.
That suddenly makes the problem much easier. Indeed, these guys have tested it on a large number of networks to see how well it works. Their test networks include Flickr, FourSquare, Frienster, Last.FM, Digg (from Dec 2010), Yelp, YouTube and so on.
And the algorithm works well. “On a Friendster social network consisting of 5.6 million nodes and 28 million edges we found a seed set in under 3.6 hours,” say Shakarian and co. For this they used an Intel X5677 Xeon processor operating at 3.46 GHz with a 12 MB Cache running Red Hat Enterprise Linux version 6.1 and equipped with 70 GB of physical memory.
That’s a promising outcome and one that many people will find valuable. Shakarian and co say that using their approach to find a seed group on the FourSquare online social network, a viral marketeer could expect a 297-fold return on investment. Not bad!
For this reason, Shakarian and co could, and probably will, find themselves and their algorithm in demand from the legion of marketers wanting to make their product viral. Not least of these could be big internet companies such as Amazon and Apple who both have huge networks of customers and plenty of products to sell.
Expect to hear more!
Ref: arxiv.org/abs/1309.2963 :A Scalable Heuristic for Viral Marketing Under the Tipping Model